Abstract
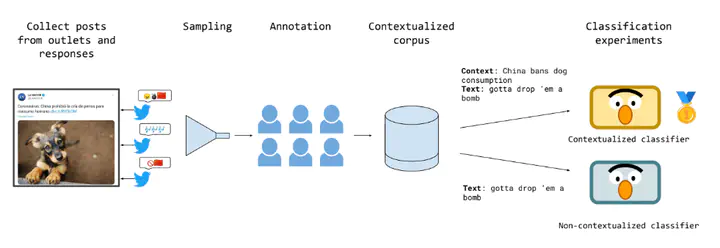
In recent years, hate speech has gained great relevance in social networks and other virtual media because of its intensity and its relationship with violent acts against members of protected groups. Due to the great amount of content generated by users, great effort has been made in the research and development of automatic tools to aid the analysis and moderation of this speech, at least in its most threatening forms. One of the limitations of current approaches to automatic hate speech detection is the lack of context. Most studies and resources are performed on data without context; that is, isolated messages without any type of conversational context or the topic being discussed. This restricts the available information to define if a post on a social network is hateful or not. In this work, we provide a novel corpus for contextualized hate speech detection based on user responses to news posts from media outlets on Twitter. This corpus was collected in the Rioplatense dialectal variety of Spanish and focuses on hate speech associated with the COVID-19 pandemic. Classification experiments using state-of-the-art techniques show evidence that adding contextual information improves hate speech detection performance for two proposed tasks (binary and multi-label prediction). We make our code, models, and corpus available for further research.